spark conf|spark executor instances : Bacolod Certain Spark settings can be configured through environment variables, which . 19 Photos. Drama. A family hiding a shocking secret starts over in Madrid, where new relationships complicate their plans and the past begins to catch up with them. Creator. .
0 · sparkconf python
1 · spark.conf.set
2 · spark submit conf
3 · spark parallelism
4 · spark external shuffle service
5 · spark executor instances
6 · spark configuration for pyspark
7 · spark conf in pyspark
8 · More
Amazon.com: sygmos 34 R34 Futanari Lolicon Rule34 Trampa Regla FUTA Futanaria Impresionantes carteles para decoración de habitaciones impresos con la última tecnología moderna sobre fondo de papel semi-brillante : Hogar y Cocina
spark conf*******External Shuffle service (server) side configuration options. Client side configuration options. Spark provides three locations to configure the system: Spark properties .
RDD-based machine learning APIs (in maintenance mode). The spark.mllib .
Spark Streaming (Legacy) Spark Streaming is an extension of the core Spark API .pyspark.SparkConf ¶. class pyspark.SparkConf(loadDefaults: bool = .Certain Spark settings can be configured through environment variables, which .
Learn how to use pyspark.SparkConf to set various Spark parameters for a Spark application. See examples, methods, and notes on how to load defaults, clone, and .Learn how to configure Spark properties, environment variables, logging, and cluster managers for your Spark applications. See the available properties, units.
The SparkContext keeps a hidden reference to its configuration in PySpark, and the configuration provides a getAll method: spark.sparkContext._conf.getAll(). .
Learn how to set and validate Spark configuration properties using SparkSession builder, SparkConf, SparkContext, and spark-defaults or spark-submit. .
Learn how to display and modify Spark configuration properties in a notebook using Python, R, Scala or SQL. See examples of spark.sql prefix and other properties.spark conf spark executor instancesRefer to Spark Configuration in the official documentation for an extensive coverage of how to configure Spark and user programs. Describe SparkConf object for the .
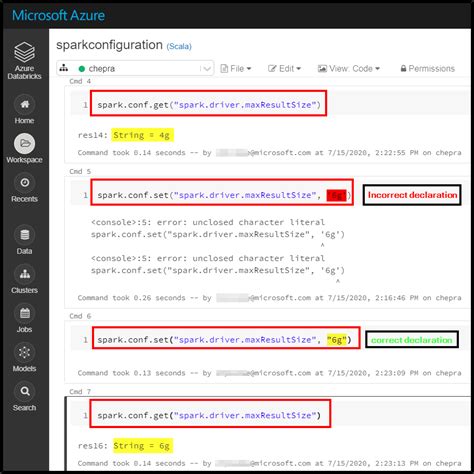
Properties set directly on the SparkConf take highest precedence, then flags passed to spark-submit or spark-shell, then options in the spark-defaults.conf file. . Spark/Pyspark Application Configuration. In this Spark article, I will explain how to read Spark/Pyspark application configuration or any other configurations .
pyspark.SparkContext is an entry point to the PySpark functionality that is used to communicate with the cluster and to create an RDD, accumulator, and broadcast variables. In this article, you will learn .The Spark shell and spark-submit tool support two ways to load configurations dynamically. The first are command line options, such as --master, as shown above. spark-submit can accept any Spark property using the --conf flag, but uses special flags for properties that play a part in launching the Spark application.The Spark shell and spark-submit tool support two ways to load configurations dynamically. The first are command line options, such as --master, as shown above.spark-submit can accept any Spark property using the --conf flag, but uses special flags for properties that play a part in launching the Spark application. Running ./bin/spark-submit --help will .Configuration for a Spark application. Used to set various Spark parameters as key-value pairs. Most of the time, you would create a SparkConf object with new SparkConf(), which will load values from any spark.*. Java system properties set in your application as well. In this case, parameters you set directly on the SparkConf object take . To set the value of a Spark configuration property, evaluate the property and assign a value. Delete. Info. You can only set Spark configuration properties that start with the spark.sql prefix. Python %python spark.conf.set("spark.sql.Configuration for a Spark application. Used to set various Spark parameters as key-value pairs. Most of the time, you would create a SparkConf object with SparkConf(), which will load values from spark.* Java system properties as well. In this case, any parameters you set directly on the SparkConf object take priority over system properties.
You can also set the spark-defaults.conf: spark.executor.memory=16g. But these solutions are hardcoded and pretty much static, and you want to have different parameters for different jobs, however, you might want to set up some defaults. The best approach is to use spark-submit: spark-submit --executor-memory 16G.SparkConf, short for Spark Configuration, acts as a gateway to customization, enabling users to fine-tune their Spark applications for optimal performance. In this detailed blog, we will explore the intricacies of SparkConf, understanding its role, key configuration options, and how it empowers developers to harness the full potential of Apache .
The Spark shell and spark-submit tool support two ways to load configurations dynamically. The first is command line options, such as --master, as shown above. spark-submit can accept any Spark property using the --conf flag, but uses special flags for properties that play a part in launching the Spark application.
Spark 2.0+ You should be able to use SparkSession.conf.set method to set some configuration option on runtime but it is mostly limited to SQL configuration.. Spark < 2.0. You can simply stop an existing context and create a new one: import org.apache.spark.{SparkContext, SparkConf} sc.stop() val conf = new .
In spark 2 you can use sparksession instead of sparkcontext. Sparkconf is the class which gives you the various option to provide configuration parameters. Val Conf = new sparkConf().setMaster(“local[*]”).setAppName(“test”) Val SC = new sparkContext(Conf) The spark configuration is passed to spark context. User Memory = (Heap Size-300MB)*(1-spark.memory.fraction) # where 300MB stands for reserved memory and spark.memory.fraction propery is 0.6 by default. In Spark, execution and storage share a unified region. When no execution memory is used, storage can acquire all available memory and vice versa.
The Spark driver program creates and uses SparkContext to connect to the cluster manager to submit PySpark jobs, and know what resource manager (YARN, Mesos, or Standalone) to communicate to. It is the heart of the PySpark application. Related: How to get current SparkContext & its configurations in Spark. 1. SparkContext in PySpark shellThe Spark shell and spark-submit tool support two ways to load configurations dynamically. The first are command line options, such as --master, as shown above.spark-submit can accept any Spark property using the --conf flag, but uses special flags for properties that play a part in launching the Spark application. Running ./bin/spark-submit --help will .
In spark 2 you can use sparksession instead of sparkcontext. Sparkconf is the class which gives you the various option to provide configuration parameters. Val Conf = new sparkConf().setMaster(“local[*]”).setAppName(“test”) Val SC = new sparkContext(Conf) The spark configuration is passed to spark context. User Memory = (Heap Size-300MB)*(1-spark.memory.fraction) # where 300MB stands for reserved memory and spark.memory.fraction propery is 0.6 by default. In Spark, execution . The Spark driver program creates and uses SparkContext to connect to the cluster manager to submit PySpark jobs, and know what resource manager (YARN, Mesos, or Standalone) to communicate to. It .
The Spark shell and spark-submit tool support two ways to load configurations dynamically. The first are command line options, such as --master, as shown above.spark-submit can accept any Spark property using the --conf flag, but uses special flags for properties that play a part in launching the Spark application. Running ./bin/spark-submit --help will .Running ./bin/spark-submit --help will show the entire list of these options. bin/spark-submit will also read configuration options from conf/spark-defaults.conf, in which each line consists of a key and a value separated by whitespace. For example: spark.master spark://5.6.7.8:7077.class SparkConf: """ Configuration for a Spark application. Used to set various Spark parameters as key-value pairs. Most of the time, you would create a SparkConf object with ``SparkConf()``, which will load values from `spark.*` Java system properties as well. In this case, any parameters you set directly on the :class:`SparkConf` object take priority .
The default Spark configuration is created when you execute the following code: import org.apache.spark.SparkConf val conf = new SparkConf. It simply loads spark.* system properties. You can use conf.toDebugString or conf.getAll to have the spark.* system properties loaded printed out. scala> conf.getAll.The Spark shell and spark-submit tool support two ways to load configurations dynamically. The first is command line options, such as --master, as shown above. spark-submit can accept any Spark property using the --conf/-c flag, but uses special flags for properties that play a part in launching the Spark application.
Adaptive Query Execution (AQE) is an optimization technique in Spark SQL that makes use of the runtime statistics to choose the most efficient query execution plan, which is enabled by default since Apache Spark 3.2.0. Spark SQL can turn on and off AQE by spark.sql.adaptive.enabled as an umbrella configuration.Configuration for a Spark application. Used to set various Spark parameters as key-value pairs. Most of the time, you would create a SparkConf object with new SparkConf(), which will load values from any spark.*. Java system properties set in your application as well. In this case, parameters you set directly on the SparkConf object take .In the following code, we can use to create SparkConf and SparkContext objects as part of our applications. Also, using sbt console on base directory of our application we can validate: from pyspark import SparkConf,SparkContext. conf = SparkConf().setAppName("Spark Demo").setMaster("local") sc = .Tuning Spark. Because of the in-memory nature of most Spark computations, Spark programs can be bottlenecked by any resource in the cluster: CPU, network bandwidth, or memory. Most often, if the data fits in memory, the bottleneck is network bandwidth, but sometimes, you also need to do some tuning, such as storing RDDs in serialized form, to .
27 de nov. de 2023 · Aroomi Kim. aroomi kim nude giving bj on her knees. in amateur, Aroomi Kim, Asian, Big Tits, Blowjob. Ass Pounding. Cumslut. Spank Butt. Peepeekun. Nice Tits. WTF. aroomi kim nude giving bj on her knees. November 27, 2023, 12:44 am 13.8k Views. Download. Read Later Add to Favourites Add to Collection. 0 share;
spark conf|spark executor instances